
In the previous article, we covered creating a URL shortener, and I explained that I selected the Twitter snowflake algorithm for generating IDs. In this article, I’ll explain the reasoning behind that choice.
Contextual
In distributed systems, creating unique IDs is essential for tasks like logging, database sharding, and maintaining data consistency. Multiple options can be used to generate unique IDs in distributed systems. The options we considered are:
Multi-master replication
Universally unique identifier (UUID)
Ticker server
Twitter snowflake
We will discuss each of them, and how they work to highlight the snowflake approach
Multi-master replication
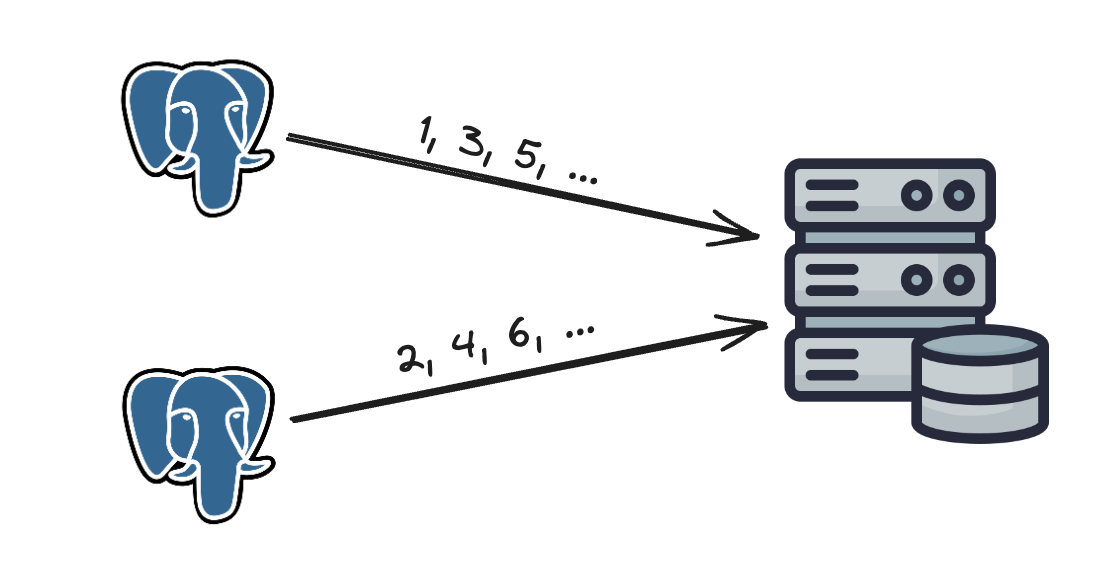
This method leverages the auto_increment functionality of databases. Rather than incrementing the next ID by 1 as usual, we increment it by k, where k represents the number of database servers in use. This helps address certain scalability issues since IDs can scale with the number of servers. However, this strategy has significant drawbacks, such as poor scalability when adding or removing servers.
UUID
The abbreviation UUID stands for Universal Unique IDentifiers. It is a 128-bit integer used for data identification in computer systems. The uniqueness of UUIDs is maintained without needing coordination between the parties that generate them.
UUID uniqueness is not zero, but it approaches it so closely that the risk of duplication is highly negligible.

Here’s an example of a UUID. We won’t delve into the detailed workings of UUIDs, but it’s important to note that they can be generated independently without server coordination, and the likelihood of duplication is extremely low. Everything is fine, but the 128-bit length of the IDs is too long for my needs in creating a URL shortener.
Ticket Server
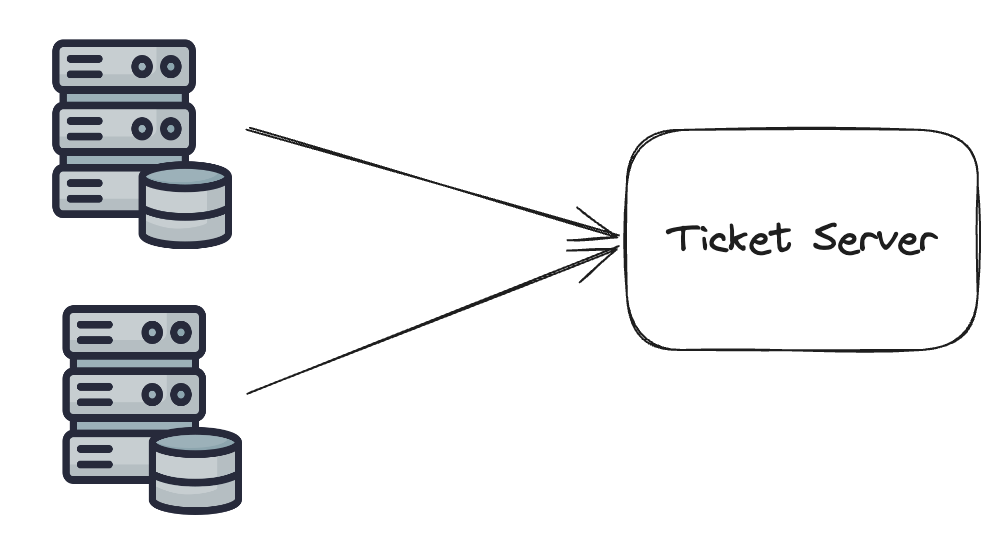
The concept of a ticket server involves utilizing a centralized auto_increment feature within a single database server (the Ticket server). All servers will connect to the ticket server, but this method is generally avoided due to the risk of a single point of failure. If the ticket server fails, all systems reliant on it will encounter problems.
Twitter snowflake
Snowflake is a service used to generate unique IDs for objects within Twitter (Tweets, Direct Messages, Users, Collections, Lists, etc.). These IDs are unique 64-bit unsigned integers, which are based on time, instead of being sequential. The full ID is composed of a timestamp, a worker number, and a sequence number.

The Snowflake algorithm generates unique IDs with some below components:
Sign bit
Reversed bit (It is always 0). This can be reserved for future requests. It can be potentially used to make the overall number positive.
Timestamp
The epoch timestamp is given in milliseconds, with Snowflake’s default epoch starting on November 4, 2010, at 01:42:54 UTC. A 41-bit timestamp can represent a maximum of 2^41-1 = 219,902,325,551 milliseconds, which corresponds to roughly 69 years. Therefore, the ID generator will be functional for 69 years. Choosing a custom epoch closer to the current date can extend the time before an overflow occurs. After 69 years, it will be necessary to either establish a new epoch time or employ alternative methods for managing IDs.
Worker ID
Worker IDs are assigned during system startup and typically remain fixed once the system is operational. Any modifications to these IDs must be carefully reviewed, as unintended changes can cause ID conflicts. The worker IDs use 10 bits, allowing for up to 1,024 worker servers to be accommodated.
Sequence
The sequence number is represented by 12 bits, providing 2^12 = 4,096 possible combinations. This field starts at 0 and is only incremented if multiple IDs are generated within the same millisecond on the same server. In theory, each machine can generate up to 4,096 new IDs per millisecond.
Conclusion
The Snowflake ID generation approach is better suited for my needs compared to other methods for the following reasons:
It is 64 bits long, which is half the size of a UUID, aligning well with our requirements.
It is highly scalable, supporting up to 1,024 machines and 4,096×1,024 requests per millisecond.
It is highly available, allowing each machine to generate 4,096 unique IDs per millisecond.
Unlike some UUID versions that lack a timestamp, Twitter Snowflake provides the advantage of sortable IDs.
That is it for this article. I hope you found this article useful, if you need any help please let me know in the comment section.
Let's connect on Twitter and LinkedIn.
👋 Thanks for reading, See you next time